The Hype about Generative AI
Unless you’ve been living under a rock, you will know that the year 2023 in tech was all about Generative AI or GenAI for short. I’m sure the hype will, of course, continue well into 2024. I’ve worked in the tech industry for long enough to see many hyped-up new trends and promising emerging technologies come and go through this hype cycle. Even Gartner places Generative AI on the so-called peak of inflated expectations in its 2023 report on the Hype Cycle for Emerging Technologies [1]. GenAI is a subset or an emerging field of models and techniques within the field of artificial intelligence, that goes beyond what we already know as descriptive, predictive and prescriptive analytics and is capable of creating or generating various types of data such as text, images, code and audio in response to descriptive text prompt. In this article, my thoughts refer particularly to text generating capabilities of GenAI which are currently the most mature and readily available for consumption in the business context.
Since we’re currently riding this peak of inflated expectations, I will share my views on what I think will be the realities that will cause a descent into the Trough of Disillusionment and some predictions on how we can climb out of that pit into the slope of enlightenment and more long-term plateau of benefits and sustained productivity.
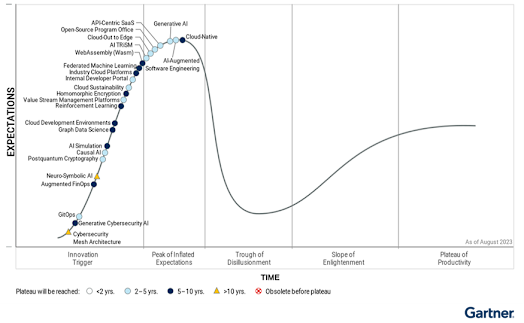
Figure 1 Source: Gartner (August 2023)
Reality #1: You need quality data, otherwise it’s garbage in, garbage out
For most organisations, the true power of GenAI will be unlocked when they connect their own organisational data with generative models.
Take a good hard look at the state of data in your organisation. Is it easy to discover? Is it timely? Is it of good quality and complete? If there are barriers that prevent your employees from effectively using your organisational data to support their decision-making and thus enable productivity, the introduction of Gen AI capabilities over the top is not going to be the magic silver bullet on its own. You will need to invest effort into improving the quality and accessibility of data.
The pre-trained large language models know nothing about your internal enterprise data but fear not, there are techniques we can use to enrich these foundational models and give them “contextual knowledge” of your internal data. The two mainstream approaches are:
1. fine-tuning and
2. retrieval augmented generation (RAG).
Fine-tuning should, in theory, deliver great results by re-training the foundational LLM on your enterprise data, but in reality, it will be impractical if not unattainable for most organisations. Fine-tuning requires vast amounts of curated data you wish to use to infuse into the foundational model, and it is extremely computationally expensive, requiring high-end GPU hardware. Fine-tuning is also a “point in time” activity, so in order to continue to refine your bespoke LLM, you would need to repeat the fine-tuning process at regular intervals. The cost, complexity, and sustainability impact of this process will likely make it impractical for most organisations.
On the other hand, the retrieval augmented generation (RAG) approach is much more straightforward and readily available for implementation. It works on the simple principle of interpreting the user’s request and then searching for relevant content chunks in your knowledge corpus before this is assembled into a prompt that is passed to the LLM. This way, we enrich the prompt with our internal contextual data so the LLM can utilise this context when generating a response and thus give you a highly specific personalised response.
Even though RAG is a much simpler concept, it still requires technical expertise to implement. You will need talented AI/data engineers who understand prompt engineering, orchestration and other critical concepts such as vector embeddings and semantic search. Your enterprise data will need to be cleansed and optimised for use with LLM service, which involves developing pipelines to crack and enrich it. In a nutshell, you will need a good data platform with capabilities enabling you to hook in and integrate it with foundational models or democratised AI services.
Reality #2: Humans are not yet superhumans
Ah, the pursuit of magical super-productivity! I’m not even convinced that’s such a good thing to aspire to anyway, but in the business world, we’re quite happy to sacrifice employee happiness in the name of unsustainable productivity. I heard far too many downright insane claims about productivity gains in the past year. For example, one of the sales guys I know claimed we’ll achieve 10x productivity in building modern data platforms. The pragmatic architect in me wants to cry out, “But how exactly do you propose we achieve that?” In the technology consulting world, bold, unsubstantiated claims like this can easily translate into selling a severely undercooked project to a client to the detriment of consultants, who are then burdened with the responsibility of delivering the results. More often than not, it boils down to engineers working excessive overtime to meet unrealistic project deadlines and being fast-tracked to burnout. Or even worse, the project quality suffers, and then the client is unhappy, too. The classic project management quality triangle of constraints or trade-offs between scope, time, and cost still holds true.
The reality is that hard empirical quantitative data on how the use of Generative AI translates to productivity gains is still limited. Most of the research on productivity gains tends to focus on highly specific tasks where it’s a no-brainer that the use of GenAI will perform well and save time. However, a typical knowledge worker doesn’t just work on these highly repetitive tasks, so an impressive time-saving on a very specific task does not necessarily translate into equally impressive productivity gains overall.
I want to look at how we can empirically measure productivity gains. First, we need some well-defined metrics by which we measure productivity. We need structured repeatable tasks that we can assign to a sufficient sample group of users and then we need to run controlled experiments where we split the sample group of users into two groups – one that uses Gen AI tools and one that does not. Only then can we compare the results for these measurable metrics. As we know, productivity metrics can be very misleading, and if we apply them as KPIs to measure employee performance, they can sometimes be misused and lead to undesirable effects. Some of the metrics that we could, for example, use for measuring the productivity of software engineers are the lines of code written or the time taken to develop a module. Likewise, for a business professional such as an analyst whose job might be to write requirements specifications or market research reports, we could use the number of documents produced or the number of words written. If we use just single-dimensional metrics like that, they can easily be hijacked to show overinflated productivity gain. With the use of Gen AI tools, it’s very easy to fluff up your writing or coding style and produce more words or lines of code, but do they hold substance or have inherent quality, too? A recent whitepaper published research findings from GitHub, which indicate downward pressure on code quality. In this research, they looked at how the use of AI assistants influences code quality by looking at churn [3]. Among other findings, GitHub research shows developers can write code “55% faster” when using Copilot. But if this initial uptick in productivity is later plagued with quality and maintainability issues that require bug fixing or refactoring, it dilutes the value of earlier productivity gain.
In conclusion, I believe we need more long-term research to more accurately pinpoint where exactly we can gain the most significant productivity uplifts and quantify them more reliably rather than rely on anecdotal and overly inflated forecasts. This insight will enable organisations to adopt the use of Gen AI and drive productivity in a sustainable fashion that delivers actual long-term value.
Reality #3: Generative AI is the cherry on the top, the icing on the cake
In my opinion, the potential of more conventional AI technology is still severely underutilised in most organisations. How many organisations out there can truly claim they are data-driven and have embedded the use of AI technologies to a systemic and transformational level? In my experience, even some of the largest enterprises in Australia in financial services or retail industries, which have vast resources available and long tradition of utilising data, have only scratched the surface of what more traditional AI methods can offer, and I would say they have at best achieved an operational level of maturity. The potential for expansion on this AI growth journey is enormous.
Traditional AI technologies, such as machine learning and natural language processing, provide organisations with valuable capabilities to analyse both numerical and textual data. These conventional methods can interpret data, automate processes and give us actionable insights. These technologies have also been around for many years and have already proven their worth across many industries, enabling organisations to enhance customer experiences and optimise operations. For instance, machine learning algorithms can help you cluster and segment your customers, which can, in turn, help you personalise recommendations and marketing campaigns, improving customer satisfaction, increasing sales or improving customer retention. Anomaly detection methods can also help across many industries to, for example, detect early equipment failures or unusual transactions, which can help reduce costs, avoid losses or improve compliance. Likewise, natural language processing technologies are well established. They can process and understand unstructured textual data, such as customer reviews or social media posts or documents, to gain valuable insights into customer sentiment, preferences and key topics.
In conclusion, while generative AI is an exciting technology, organisations should not overlook the benefits of adopting more traditional AI technologies. These established technologies provide valuable capabilities that have already proven their worth in various industries. I envision that organisations will have to invest in adopting these more traditional AI technologies and combine them with Gen AI as a cherry on top to unlock the true transformative potential. Skipping ahead to just embracing Gen AI will not cut it. It should be seen as an additional layer of innovation that should be explored as organisations also fully embrace and integrate traditional AI technologies into their operations.
References
[1] Gartner Places Generative AI on the Peak of Inflated Expectations on the 2023 Hype Cycle for Emerging Technologies, https://www.gartner.com/en/newsroom/press-releases/2023-08-16-gartner-places-generative-ai-on-the-peak-of-inflated-expectations-on-the-2023-hype-cycle-for-emerging-technologies
[2] The Impact of AI on Developer Productivity: Evidence from GitHub Copilot, https://arxiv.org/abs/2302.06590
[3] Coding on Copilot: 2023 Data Suggests Downward Pressure on Code Quality, https://www.gitclear.com/coding_on_copilot_data_shows_ais_downward_pressure_on_code_quality


Comments
Post a Comment